


VIII. Déploiement d'une architecture LDAP▲
Après avoir vu comment écrire un schéma, nous allons étudier le processus de mise en œuvre d'un annuaire LDAP.
VIII-A. Phase de cadrage▲
La première phase du processus de mise en œuvre d'un annuaire est la phase de cadrage. C'est pendant cette phase que doivent être désignés tous les objectifs qui sont assignés à l'annuaire.
Quel que soit le type d'organisation dans laquelle un annuaire est déployé, celui-ci a toujours un impact important. Le service informatique est bien sûr le premier à être concerné, mais il est loin d'être le seul. Il est donc important que l'organisation désigne un responsable annuaire, qui sera l'interlocuteur unique entre le prestataire qui met en œuvre l'annuaire, mais aussi entre les utilisateurs finaux et le service informatique.
L'annuaire est amené à devenir le point central de l'architecture informatique de l'organisation. Toute application nécessitant une authentification des utilisateurs devrait s'appuyer sur un annuaire. C'est là sa première vocation et sa première utilisation. Mais il est aussi possible de l'utiliser pour stocker des informations supplémentaires sur les personnes, et peut ainsi être la base de données d'une application de type « pages blanches ». On voit bien alors qu'il peut servir pour gérer presque n'importe quel type de données, et dans beaucoup d'applications.
Il est donc primordial, pendant la phase de cadrage, de se donner des priorités parmi toutes ces possibilités d'utilisation d'un annuaire. Il faut, d'une part, choisir quelles seront les premières applications qui appuieront leur authentification sur l'annuaire. Il faut aussi, d'autre part, déterminer quelles sont les premières applications qui utiliseront les données de l'annuaire en tant que telles.
L'important à cette étape est de rester modeste et pragmatique. Avoir une ou deux applications s'appuyant sur l'annuaire est un bon début, qui permet de démarrer simplement, sans faire la révolution dans tout le système informatique. Avoir une application de type pages blanches et un serveur mail dont l'authentification et les paramètres de messagerie sont basés sur l'annuaire est un bon début. Ce n'est pas la peine d'y ajouter tout de suite une liaison avec le logiciel de paie et la gestion des permissions du serveur de fichiers.
L'autre paramètre à intégrer dans cette phase concerne les utilisateurs. Dans le cas de la mise en œuvre d'une application pages blanches, ou bien d'une autre application nouvelle entièrement basée sur l'annuaire, ils doivent être intégrés au plus tôt dans la définition des besoins. En effet, au-delà des données techniques, l'utilisateur final sera le plus compétent pour dire quelles sont les données qui devront être intégrées à l'annuaire.
VIII-B. Phase de conception▲
VIII-B-1. Choix des données et Identification des acteurs▲
VIII-B-1-a. Déterminer les données de l'annuaire▲
Après la phase de cadrage, la première étape de la phase de conception consiste à énumérer les données présentes dans l'annuaire. Il s'agit d'énumérer de manière exhaustive d'une part toutes les classes d'objets amenées à peupler l'annuaire, et d'autres parts, pour chaque classe, quelles sont ses propriétés gérées par l'annuaire.
Pour chaque type de données, en procédant par classes d'objets puis par propriétés si nécessaire, il faut alors déterminer les informations suivantes :
- Quelles sont les personnes ou les applications manipulant cette donnée? On se contentera dans un premier temps d'une réponse sommaire, sachant qu'une réponse plus complète - par type d'action - sera donnée par la suite.
- Quelle est la ou les sources actuelles de cette donnée ? Est-elle déjà sous forme numérique ou pas encore ? Est-ce une donnée statique ou dynamique ? Est-elle calculée ?
- Quel est le type de cette donnée (chaîne de caractères, entier, data, etc)? Quel est son format : la chaîne est-elle encodée en utf8 ou unicode? Quel format de date est utilisé ? Sa taille ?
- Quelle est la pérennité de la donnée ? Sa fréquence de mise à jour ? Cette mise à jour est-elle automatique ou manuelle ?
VIII-B-1-b. Cas d'utilisation▲
Une fois les données de l'annuaire bien définies, il faut détailler leur utilisation. Pour y parvenir de façon convenable, il est utile d'employer la même méthode que lorsqu'on décrit des cas d'utilisation, en eXtrem Programming et en modélisation UML.
Bien que les cas d'utilisation soient centrés sur les utilisateurs, il faudra, dans notre travail, énumérer aussi les actions des applications externes à l'annuaire, mais qui l'utilisent.
Pour chaque donnée contenue dans l'annuaire, il faut donc noter qui effectue les actions suivantes :
- Recherche. Une recherche s'effectue sur certains attributs. Pour chaque objet, dans chaque cas d'utilisation, il faudra donc noter les attributs sur lesquels la recherche s'effectue.
- Lecture. Là encore il faut tenir compte des attributs. Les cas d'utilisation devront contenir l'information «de quel attribut a besoin de lire telle personne sur tel objet.»
- Création. Lors du processus de création des objets dans l'annuaire, il faudra valider que la personne, ou l'application, qui crée un objet, a bien connaissance de toute l'information nécessaire. Il peut arriver que cela ne soit pas le cas. Par exemple, une personne du département ressources humaines ne pourra pas d'elle-même assigner un login à un utilisateur dans l'annuaire. Il faut prévoir un mécanisme, en dehors de l'annuaire, qui lui fournit cette information qui se peut se révéler nécessaire dans certains cas.
- Modification. Dans l'écriture des cas d'utilisation comprenant des modifications, il est nécessaire de noter quels attributs sont modifiés, et de quel type de modifications il s'agit: ajout d'une valeur, retrait d'une valeur, modification de toutes les valeurs, etc.
- Suppression.
LDAP ne contient pas l'équivalent de clé étrangère pour contrôler la cohérence des données de l'annuaire.
Les cas d'utilisation peuvent dans un premier temps être effectués sur les classes, sur les catégories d'objets présents dans l'annuaire. Il sera parfois nécessaire de descendre à un niveau de précision inférieure et d'écrire les cas d'utilisation par attribut, ou par groupes d'attributs.
Il sera aussi utile noter la fréquence de chaque cas d'utilisation.
VIII-B-2. Élaboration du schéma▲
Cette étape s'appuie essentiellement sur l'étape précédente du choix des données contenues dans l'annuaire. Elle consiste à écrire un schéma qui modélise ces données.
Écrire un schéma c'est essentiellement définir :
- les attributs
- les classes
- la hiérarchie entre ces classes
des objets qui constitueront l'annuaire.
De la liste des données, il faut extraire les informations élémentaires, sous la forme d'une liste d'attributs, et d'une liste de classes, celles-ci étant définies en regroupant les attributs. Notre méthode consistera à définir et modéliser les attributs, indépendamment des classes, les attributs étant partagés entre classes; puis à constituer les classes d'objet en agrégeant les attributs adéquats.
Entre la définition des classes et celle des attributs, il peut y avoir une démarche itérative. Ainsi certaines informations élémentaires changeront de statut au cours de la modélisation. Par exemple la catégorie d'une personne pourra être une classe, plutôt qu'un attribut, parce que l'appartenance d'une personne à une catégorie implique la présence obligatoire d'autres attributs.
Lors de la définition des attributs comme celles des classes, il faut penser à utiliser la relation d'héritage, lorsque des caractéristiques sont partagées et qu'il existe des liens de spécialisations, entre attributs ou entre classes.
En reprenant ce qui a été écrit précédemment, définir un attribut consiste à définir :
- son nom;
- s'il est standard, issu d'une RFC, public, déjà créé et publié, ou encore spécifique, spécialement créé;
- son attribut père, s'il dérive d'un autre attribut
- sa syntaxe: est-ce une chaîne de caractères ? Un pointeur vers une autre entrée de l'annuaire ? Etc.
- s'il est mono ou multivalué;
- par quelle(s) classe(s) il est utilisé;
- sa fréquence d'utilisation
Il peut arriver que l'on ait distingué des attributs contenant exactement le même type d'information parce qu'ils étaient attributs de classes différentes. Cette différenciation n'a pas lieu d'être. Au contraire, il est plus logique d'avoir un même attribut utilisé par plusieurs classes.
De façon similaire, la définition des classes d'objets consiste à préciser :
- son nom;
- si elle est standard, issue d'une RFC, publique, ou spécifique;
- sa classe mère, si elle dérive d'une autre classe;
- la liste des attributs obligatoires;
- la liste des attributs facultatifs;
VIII-C. Sécurisation▲
Bien qu'étant primordial, ce chapitre sera assez court. En effet, la sécurisation de l'annuaire s'appuie sur les éléments cités précédemment, et sur des éléments à venir.
Tout d'abord, les cas d'utilisation, par classe puis par attribut, permettent de définir les droits d'accès à la granularité nécessaire.
Il s'agit donc ensuite d'écrire les règles d'accès, en s'appuyant sur la syntaxe présentée au chapitre Fonctionnement des permissions dans OpenLDAP.
La topologie du service influence aussi la sécurité.
VIII-D. Développement de l'arbre informationnel▲
Comme on l'a vu aux deux premiers chapitres, les données d'un annuaire sont organisées sous forme hiérarchique, en arbre. Concevoir l'arbre informationnel d'un annuaire c'est spécifier la forme de cet arbre, son organisation, comment les données vont y être nommées. L'objectif à cette étape est donc d'organiser les données pour leur :
- Consultation
- Mise à jour
- Duplication
- Répartition
VIII-D-1. La structure de l'arbre informationnel▲
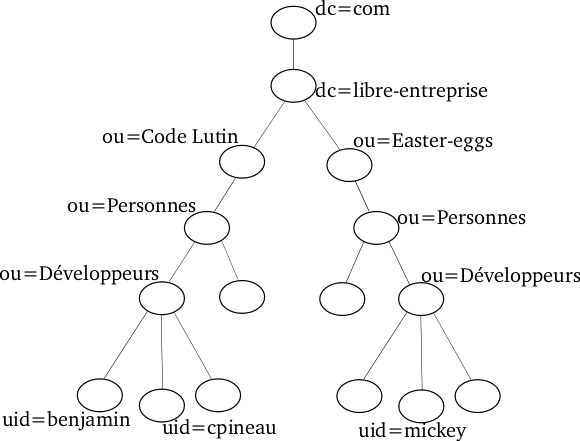
Un arbre est caractérisé par son branchage plus ou moins fort. Un arbre a un branchage faible lorsque les entrées feuilles (sans descendant) sont très regroupées, au lieu d'être dispersées sous d'autres entrées. On dit aussi qu'il est plat.
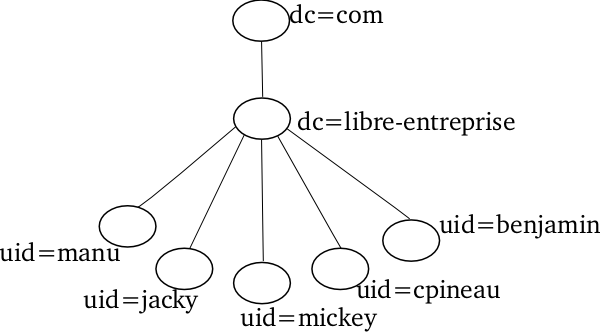
Les arbres plats ont pour principal avantage que les recherches s'effectuent rapidement, parce que le serveur n'a pas à parcourir toutes les branches, et à faire une recherche par branche. Par ailleurs les arbres plats présentent beaucoup d'inconvénients :
- Les collusions de RDN peuvent se produire fréquemment;
- La mise en place de referral n'est pas possible (Le mécanisme de referral peut alors être remplacé par la mise en place d'un méta annuaire. Néanmoins un méta annuaire est beaucoup plus lourd à mettre en place.)
Sur ces points les arbres à fort branchage sont bien plus efficaces. Ils facilitent aussi la délégation. L'inconvénient des arbres à fort branchage apparaît essentiellement lorsque la structure de l'arbre reflète la structure de l'organisation, et que cette structure est amenée à être modifiée. Dans ce cas, les entrées de l'arbre vont elles aussi être amenées à changer de place et de DN, ce qui peut provoquer des problèmes de cohérences.
Il y a donc un certain équilibre à atteindre entre les deux types d'arbres. Les éléments à prendre en compte sont les suivants (4) :
- Le nombre d'entrées prévu et son évolution ?
- La nature (type d'objet) des entrées actuelles et futures ?
- Vaut-il mieux centraliser les données ou les distribuer ?
- Seront-elles administrées de manière centrale ou faudra-t-il déléguer une partie de la gestion ?
- La duplication est-elle prévue ?
- Quelles applications utiliseront l'annuaire et imposent-elles des contraintes particulières ?
- Quelles permissions seront mises en place?
VIII-D-2. Le nommage des données▲
VIII-D-2-a. Choix du suffixe▲
Contrairement aux annuaires X500 les annuaires LDAP n'ont à vocation à s'insérer dans un annuaire universel. Dès lors, contrairement à leurs ancêtres, chaque annuaire peut avoir la racine qu'il veut. Il n'existe pas d'obligation à respecter. La norme X500 imposer aux annuaires d'entreprises parisiennes d'avoir un suffixe de la forme l=paris,o=fr.
Dans la norme LDAP chaque annuaire fait ce qu'il lui plaît, et peut prendre comme racine, comme suffixe, ce qu'il veut. Le suffixe est devenu l'identifiant d'un annuaire.
Il existe néanmoins une RFC, la [rfc2377] qui apporte un peu de cohérence dans le choix des suffixes. Elle permet de construire un suffixe à partir d'un nom de domaine, et en utilisant l'attribut dc. Cette RFC propose tout simplement de transformer tous les éléments d'un nom de domaine en valeur de l'attribut dc. Ainsi l'annuaire l'entreprise dont le nom de domaine est easter-eggs.com sera dc=Easter-eggs, dc=com.
VIII-D-2-b. Nommage des entrées▲
Le nommage des entrées consiste à choisir un attribut, qui sera utilisé pour nommer les entrées. Il s'agit donc de choisir le RDN de chaque branche. Cet attribut doit permettre de désigner sans ambiguïté une entrée. C'est-à-dire que sa valeur doit être unique dans chaque branche. Le deuxième élément à prendre en compte est sa stabilité. Il est préférable en effet qu'une entrée ne change guère d'identité. Cela est d'autant plus vrai dans le cas des entrées possédant des descendants.
VIII-E. Topologie du service▲
Définir la topologie du service consiste à définir la répartition géographique de l'annuaire. Un annuaire LDAP peut en effet être déployé sur des machines physiques différentes. Cette étape a but de concevoir cette répartition.
VIII-E-1. Conception▲
VIII-E-1-a. Objectifs▲
Disposer des serveurs annuaires sur des plusieurs machines permet de répondre à un besoin en qualité de service. S'ils sont bien répartis et bien configurés, plusieurs serveurs seront plus performants et plus fiables qu'un seul serveur. La répartition de l'annuaire sur plusieurs machines peut aussi faciliter sa gestion.
La norme LDAP définit deux mécanismes permettant une répartition géographique des serveurs. Le premier est le mécanisme de referral qui permet de déléguer une branche d'un annuaire à un autre annuaire, localisé sur une machine distante. Le deuxième est le mécanisme de réplication.
La mise en place des deux mécanismes dépend très fortement de la structure de l'arbre informationnel. Le processus de conception de la topologie du service peut donc être itératif avec la conception de l'arbre informationnelle.
VIII-E-1-b. Recueil des informations▲
La première étape consiste à faire l'inventaire des sites géographiques qui devront se connecter à l'annuaire. Pour chaque site il est nécessaire ensuite de dessiner son schéma réseau pour identifier les différents réseaux, les différents routeurs et surtout par quelle machine passe les flux sortants. Les liaisons entre sites devront aussi être répertoriées et leurs caractéristiques (débit, réseau privé ou public) devront être notées. Cette étape est donc l'identification des contraintes réseau.
Pour chaque site, il faut ensuite évaluer le nombre d'utilisateurs et en déduire le nombre de requêtes qu'ils génèrent et le type de requêtes (interrogations, mises à jour, création, etc.). Cette étape réutilise donc les cas d'utilisation déjà produits précédemment.
La troisième information à noter sur les requêtes, outre leur nombre et leur type, est l'information concernée par la requête. Par exemple, est-ce qu'il s'agit de l'identité des utilisateurs, des attributs de messagerie, ou bien de leur numéro de téléphone.
VIII-E-1-c. Les décisions techniques▲
Nous avons alors à notre disposition :
- la topologie du réseau;
- les flux générés par certaines parties du réseau vers l'annuaire, ces flux étant eux même composés de flux de recherche, de lecture, d'écriture, etc.;
- l'arbre informationnel, qui contient l'information recherchée, lue ou modifiée par ces flux.
À partir de toutes ces informations, nous devons définir la topologie du service LDAP, soit répondre aux deux questions suivantes :
- L'information doit-elle être répartie sur un ou plusieurs serveurs ? Et comment?
- Quelle redondance ?
La répartition du contenu de l'annuaire entre plusieurs serveurs n'est possible que si l'arbre informationnel le permet. Il y a donc une démarche itérative entre la définition de la topologie et le choix de l'espace de nommage.
Les deux sections suivantes donnent d'avantage d'information sur le service referral, et sur la réplication.
VIII-E-2. Utilisation de referral▲
Le mécanisme de referral est un mécanisme de redirection qui permet à un serveur annuaire de déléguer une partie de ses branches à un autre serveur. Dans le protocole LDAP décrit dans [rfc2251] le serveur peut toujours répondre à une opération quelconque par un referral.
La [rfc2251] décrit en particulier uniquement comment un serveur doit répondre à une recherche dont les entrées retournées sont réparties sur plusieurs autres annuaires. La réponse du serveur doit alors contenir les entrées gérées par lui-même, et une ou plusieurs références, des url que le client doit exécuter pour terminer sa recherche.
Les RFC de la version 3 de la norme ne définissent pas davantage comment un serveur a connaissance des branches qu'il doit déléguer. La [rfc3296] est une proposition pour remplir cette lacune. Openldap s'appuie dessus.
Cette RFC introduit une classe d'objets, la classe referral, possédant pour seul attribut ref. Cette classe représente une référence inférieure dans l'annuaire, c'est-à-dire une branche déléguée à un autre serveur. L'attribut ref contient une url LDAP. Néanmoins elle ne doit pas contenir de profondeur, de filtre ou d'attribut. Son usage est distributedOperation.
À chaque fois qu'un client tente d'accéder à une entrée située une entrée de type referral, ou bien sous une de ces entrées, l'annuaire renvoie donc en referral les valeurs de l'attribut ref de l'entrée referral. Il est néanmoins possible d'ajouter le contrôle ManageDsaIT aux opérations, pour pouvoir modifier les entrées elle même.
Openldap utilise aussi un default referral. Ce referral est renvoyé par défaut à toute les requêtes effectuées sur le serveur et dont le base_dn n'est sous aucun suffixe du serveur.
Le chaînage, mécanisme par lequel le serveur contacte lui même un autre serveur et envoie sa réponse au client, n'est pas mis en place dans Openldap et n'est guère déployé ailleurs pour des raisons de sécurité. Néanmoins les mécanismes de meta annuaire permettent ce type de configuration.
VIII-E-3. La réplication▲
Alors que le mécanisme de referral permet de répartir l'information d'un annuaire entre plusieurs serveurs, la réplication permet quant à elle de dupliquer cette information sur plusieurs serveurs.
Les mécanisme, referral et réplication, ont des points communs et des différences. Leur point commun est qu'ils impliquent tous deux une répartition géographique des serveurs. En cela ils permettent d'intervenir sur la qualité de service de l'annuaire. Mais les moyens mis en œuvre diffèrent.
La réplication introduit de la redondance. Cette redondance permet :
- Tolérance aux pannes. Si un serveur ne répond plus, il sera possible pour le client de contacter un autre serveur contenant l'information.
- Équilibrage de charge. Les clients LDAP seront configurés pour contacter le serveur annuaire le plus proche d'eux.
- Gestion locale des données. Le mécanisme de réplication permet à chaque entité géographique de gérer elles-mêmes les données qui dépendent d'elle, et de les partager en lecture aux entités.
VIII-F. Vue d'ensemble▲
|
Phase |
Aspects fonctionnels |
Aspects techniques |
|---|---|---|
|
Phase I |
Cadrage
|
Il n'y a pas d'aspect fonctionnel à cette étape |
|
Phase II |
Choix des données et Identification des acteurs
|
Écriture du schéma
|
|
Phase III |
Définition des droits d'accès |
Écriture des clauses d'accès |
|
Phase IV |
Conception de l'arborescence |
Topologie du service
|